


If you’ve not read the article before ” Nuts & Bolts of Tally Filesystem: Embedded Indexing” If you haven’t, please take the time to read it to better understand this section, else you’ll feel as if your friend has tricked you into watching a second part of a film without having watched the first part.
It was in the article before, “The tally db is one of the multiple phoenixes of the tally product, that keeps rediscovering itself to keep pace with the raising requirements of the ever-emerging Tally product to simplify how you run your businesses.”
If a new data pattern is detected within the Tally product without second thought, we at Tally will begin the process of re-discovery. One such possibility was discovered in the shape of GST. We found a myriad of data patterns after the introduction of the GST regime. One particular data pattern led to RangeTree.
With the introduction GST, Tally wanted to make sure that it was easy for users. GST, Tally wanted to provide a user-friendly GST user experience for tax-related compliance. However, it has to be completed quickly to ensure it is possible that Tally users can begin to follow the tax regulations from day 1 of their obligation. Many new applications have been proposed and one of them concerns GST reports. Functionally Tally was able to provide GST reports providing all the information required by Tally users in the first GST versions of Tally however, customer feedback received from market about the time required to fill the GST reports is at the first priority to be addressed or improved on.
For Rel3.0 of Tally, we wanted to create GST reports more efficient and enjoyable to be able to see our Tally customers happy and having more time to run their companies.
What was happening when GST reports are opened:
To create GST reports, the bulk of the time was spent into calculating the data voucher wise, and deciding the individual application for each of the GST buckets. However, these calculations were essential for having a fresh and current information on the status of GST reports in the event that reports were requested.
Should we compute prior to entering GST reports? GST reports? Yes, we can perform the pre-computations prior to vouchers being modified or created and then store them on disks so that the reports can be generated quicker since the calculations are readily accessible.
What is the reliability or accuracy of these calculations when the maters utilized in the vouchers have been changed. For e.g. the stock item that is that is used to create the voucher has changed in tax classification and tax rate details have been changed. If these changes are made in the master’s account, the pre-computations made depict outdated values.
Thus, pre-computations improve the speed of reports, but how to deal with the master modifications that could make these calculations outdated.
If a master’s value is altered do we need to create an inventory of the vouchers in which the master is taking part in and then re-computations? In this is how each master alteration will require a large number of vouchers in order to complete. Do we have the ability to update the pre-computation in the future and then accept the master as it is in the meantime? This would mean that subsequent vouchers to be created or altered to have current pre-computations. The only issue that was not addressed was the method of updating vouchers which were changed or created prior to the master modification.
When a master alteration occurs, if we are able to mark all existing vouchers as old and they could be picked up to be re-computation later in the worst case, just prior to filling out GST reports. This would require many ios to look through every coupon and label them old and make master alteration one that is time-consuming.
We now want faster GST reports. At the same time, it must not impact on the existing functions such as master alteration. To add a new level of complexity, there may be multiple master changes throughout the cycle. Performing computations for identical vouchers over and over is inefficient and can reduce productivity. If we could store the reference to a specific group of vouchers affected by master changes and continue to add more vouchers to the collection based on another master’s alteration, we can avoid repetition of the voucher re-computations.
Can Embedded Indexing be used in all use cases?
In the present TPFS (Tally’s proprietary File System] the records are connected to one through embedded tree links. To mark all vouchers as stale using masters, we need to scan each voucher to mark them expired. Similar to this, we must perform this for each master which will undergo alterations prior to accessing our GST reports.
This mark can result in a large number of io’s because we need to be able to read the vouchers marking the vouchers and keep in them.
Furthermore, when we need to compute a re-computation for the affected voucher in order to find out what vouchers have been classified as stale, we have to walk through all vouchers that are in the company and then review each voucher for staleness. then use it to be computation.
The main issue with this strategy is that it creates more Io’s, which in turn takes more time.
To make it easier to understand the problem that an master [ledgers and stock items, or all elements involved in financial transactions are known as masters] gets changed, vouchers associated with this master could be affected, and these vouchers will need to be recalculated.
Let’s say that vouchers that have below ID’s are affected by modifying the master m1 of a voucher:
1, 2, 3, 4, 5, 34, 36, 38, 39, 45, 56, 57, 89, 357, 358, 415, 568, 569, 790, 857, 858, 859, 923, 1023, 1024, 1059, 1067, 1256, 1267…….
Below ID’s can be affected by altering a master m2:
91, 92, 198, 199,200, 201, 203, 204, 345, 356, 412, 413, 418, 567, 570, 789, 856, 934, 935, 936, 937, 1025, 1026, 1027, 1039, 1057, 1200, 1259, 1268…………………
In this manner, the masters of multiple masters have been altered, vouchers affected are accumulating.
Taking steps towards the solution:
By keeping index into the records, the records become dirty and needs to be written to disk. Writing to disk consumes time and in turn increase the time to complete the user operation. In this case when master is altered then indexes are to be embedded into all the vouchers that are impacted
due to this alteration. Due to this all the voucher records that become modified due to the embedded indexes are to be written to disk in turn increasing the time taken to accept a master. This will impact the master acceptance time which is a day-to-day operation while using Tally.
Maintaining a separate list of voucher identifiers might be a solution. To further optimize the usage of disk usage to maintain the list of voucher identifiers, can a bit map be used?
In keeping an index in the documents, the records get filthy and need writing to disk. Writing to disk is time-consuming and can increase the time required to complete the user’s operation. In this scenario, if masters are altered, indexes must be incorporated into all vouchers that have been affected.
Due to this change. Because of this, all voucher records that are modified because of embedded indexes will be transferred to disk, making it more time-consuming to accept master records. This can affect the master acceptance time, which is a normal day-to-day process making use of Tally.
The creation of a distinct list of voucher identification numbers could be an option. To optimize the use of disks to keep this list of voucher identification numbers can a bitmap be utilized?
BitMap and its geography:
Bit maps are an image of bits in it is that the position of the bit is used to represent the identifier’s value.
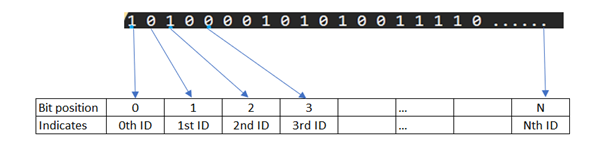
What will be the maximum size of bitmap in this use case:
The bitmap is theoretically should support the maximum range of the identifier which it is representing, in this case the unique identifier of the voucher let’s call it voucher id.
The voucher id is of 4 bytes length due to technical reasons of the language in which the product has been coded.
- Voucher identifier (id) length in tally = 4bytes = 4*8 bits per byte = 32-bit number.
- Biggest voucer id can be 2 Power 32 = 4294967295.
- So ideally one bitmap can grow till (4294967295 / 8 bits per byte) = 53,68,70,911 bytes approximately 511MB.
Bit Map should be able to represent 1 to 2 power 32 (4294967295 ~= 511 MB)

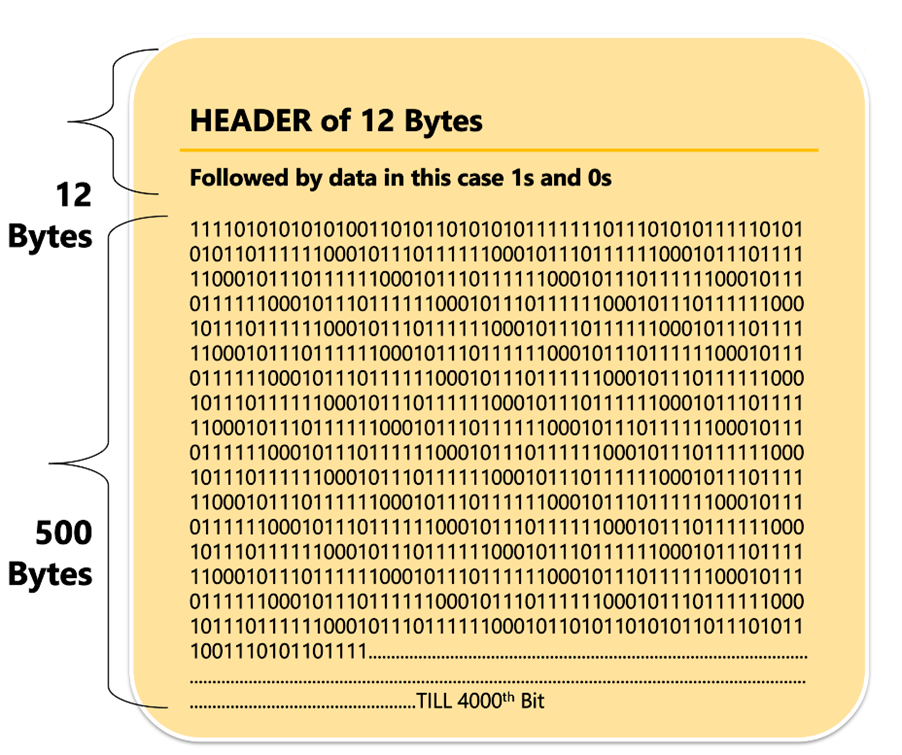
How can a 512-byte Tally block be used to represent the 511MB of data: introducing Leaf Block
Each Tally block of data consists comprised of 512 bytes. It is also exempt from some header data, for example, if we have twelve bytes worth of header information. We are left with 500 Bytes disk space each block to hold information.
Each block therefore can represent the identifiers of 4000 [500 * 8 bits per block]
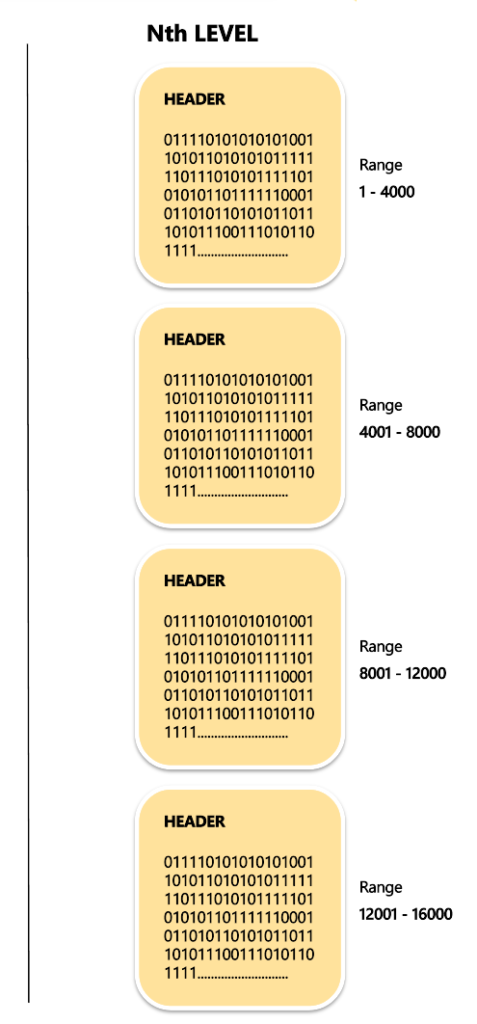
How to tame the horses: introducing Non-Leaf Block
Theoretically, there are 10 lakh leaf blocks. Attempting to reach them on the disk in a random manner could impact the performance of fetch. To complete the fetch optimally, we can store the offsets for the leaf block within a separate block. The offsets from different leaf blocks could be put within a block just containing offsets of the leaf blocks. This block, which stores all offsets is known as”NON-LEAF BLOCK” ” NON-LEAF BLOCK”.
Four Bytes offset i.e. In this (N-1)th stage, a block that is not leaf that leaves the block header of 12bytes could store 500bytes or 4Bytes = 125 offsets.
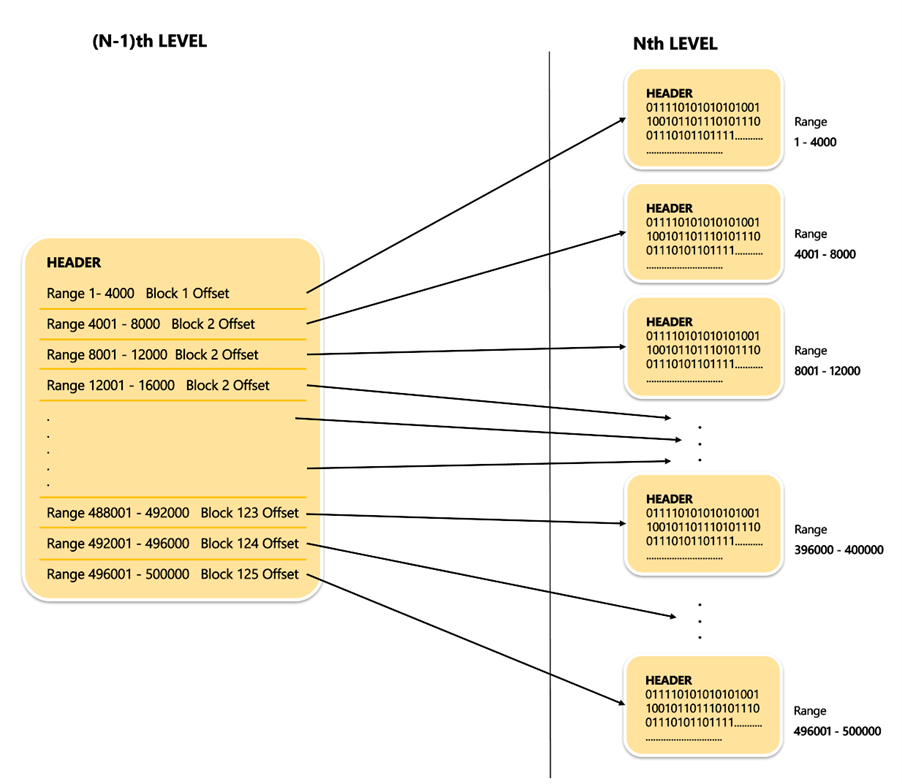
This (N-1)th Level for a full range of 2 Power 32 will look as below :
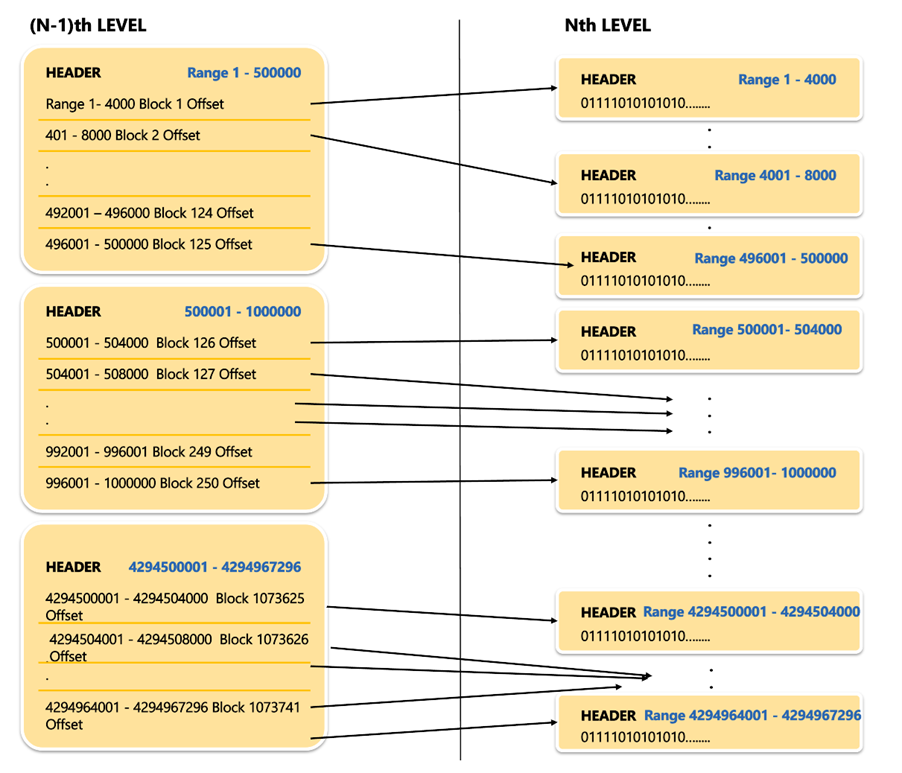
The process of reaching out to the necessary voucher ID value:
At each level, there will be a problem of number of blocks that are greater than one and because of this the ability to reach a specific block has to be optimized. In order to do this, if an additional level is created using non-leaf blocks, at around (N-3)rd stage, we arrive at the point where the whole range of 1 to 232 is reached through the reference to a single block that is referred to the Root Block or the ground zeroth level block. By using it as the Root Block, one are able to determine if a particular voucher ID is set to 1 or 0 depending on the level at which it will be taken to re-computation.
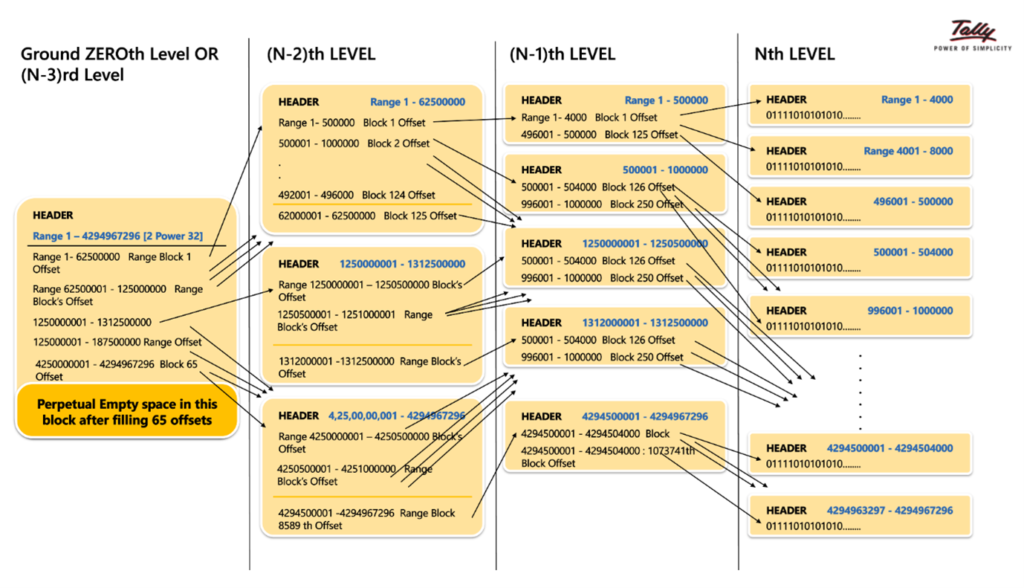
These RangeTree blocks will become available only in the event that data is available in the appropriate Leaf Node Path. The blocks at every level are generated on demand whenever the requirement for storage of data arises, not a fully filled block set being created by empty blocks. One way for simple visualization is listed below. Only the blocks that are absolutely essential are built.
Summarizing:
In cases where fetch needs to be quicker, the size of data must be less, however since the nodes that are involved are very dense and the Range Tree Range Tree can be used to solve both on-disk and in-memory scenarios. In this case the moment a master is modified, the vouchers associated with it are marked to be recalculated using the range tree. As the master’s alterations continue to grow, as it occur, more vouchers are identified. A voucher that was already affected by master1 may be marked when a master2 has been modified. Once Tally’s Tally company user ready to perform the re-computation, it will be initiated by entering GST reports. When the re-computation is completed and the pre-computation has been updated, the reports will be updated with maximum speed. To pull/populate GST reports using minimal input output and with a minimum of time, numerous such improvements have been implemented within the software in the past. Range Tree has contributed a tiny amount of efficiency optimization to this effect.
We’ll be again with a new and insightful insight into another data structure or ‘nut and bolt that runs within the tally program to give you the most secure and efficient experience with your most loved business reports.
As you wait, we wish you lots of cheers, enjoyment in learning something new.